

온라인 가격 시장 조사를 하려면 여러 사이트를 전전하게 됩니다. 네이버, 쿠팡 등 여러 플랫폼에 가격을 조사하다 보면, 온라인 가격 시장 조사가 거의 노가다 (?) 처럼 되버리죠. 사실 내가 원하는 것은 이미지, 가격, 등록일, 리뷰 수 정도인데 이런 것을 하나 하나 적다보면 너무 힘이 빠집니다.
그래서 오늘은 비교적 가격 정보가 잘 나와 있는 “다나와” 사이트를 참고하여 가격 정보를 받아 볼 수 있는 파이썬 코드를 작성해봅니다. 다나와 사이트에 부하를 주거나, 다른 용도로 사용하면 법적 문제가 있습니다.
저는 개인적으로 해당 코드를 사용하지는 않고 단순히 공부 용도로 사용하는 것이니 큰 오해는 하지 말아 주세요!
1. 온라인 가격 시장에 앞서
먼저 내가 조사하는 정보를 정해야 합니다. 원하는 정보를 웹 페이지에서 보여주고 있느냐가 해당 사이트가 적합한지 아닌지 판단을 할 수 있기 때문입니다.
저는 A 상품군에 제품명, 가격, 부가정보, 사진, 등록일, 리뷰 수 정도가 필요합니다. 제가 찾고 있는 A 상품군에는 일반적으로 제품명에 제조사 또는 유통사 이름이 들어가기 때문에 제품명이 중요합니다. 또한 등록일은 해당 제품의 대략 출시일을 예측하기 위해 사용할 예정입니다.
리뷰 수나 부가정보, 사진등은 제품을 비교할 때 사용하기 위함이고 간단한 썸네일도 받아서 엑셀로 정리해보려고 합니다.
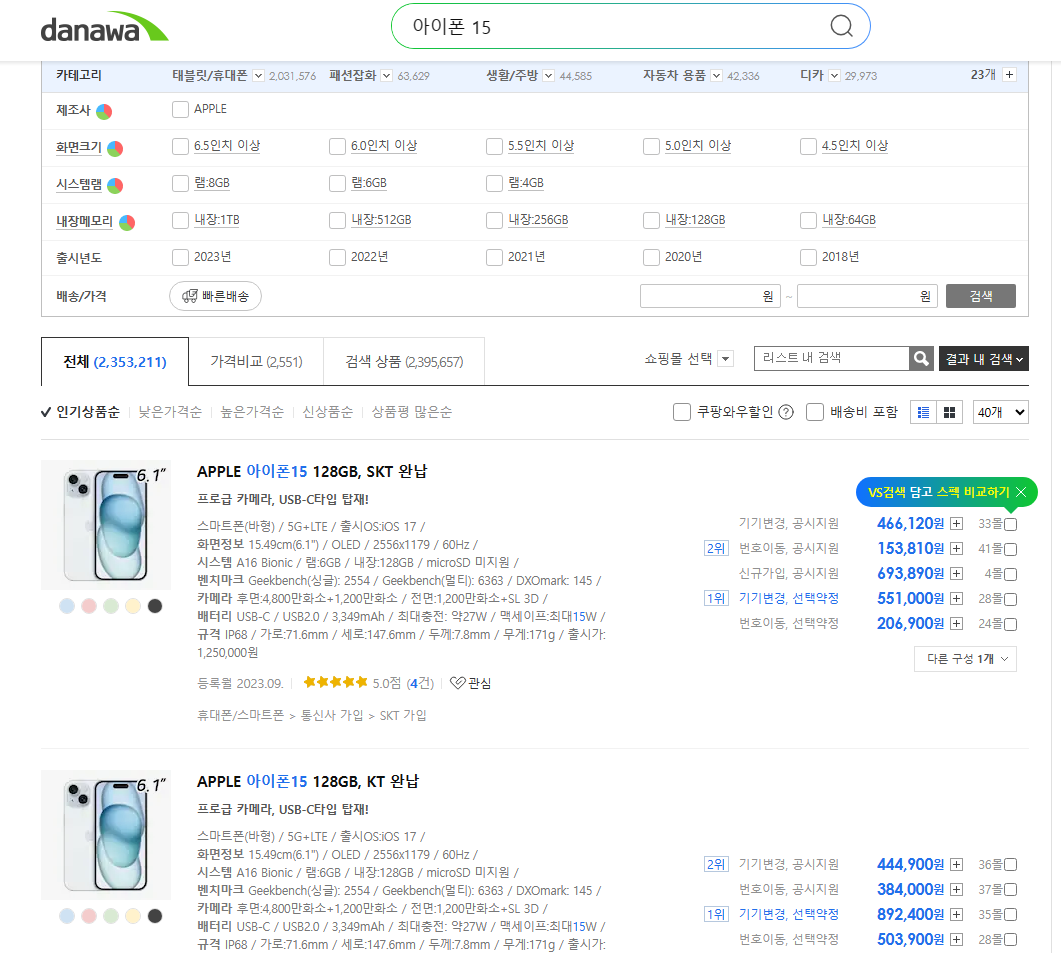
아이폰 15 : 다나와 통합검색 (danawa.com)
아이폰 15 통합검색 : 다나와 통합검색
‘아이폰 15’의 다나와 통합검색 결과입니다.
search.danawa.com
아이폰 15라고 다나와에서 검색을 하니, 여러 사이트의 최저가 가격을 보여주고 있습니다. 사실 저는 아이폰을 구매하거나 아이폰 가격 비교를 하려고 하는 것은 아니지만, 다나와 사이트가 비교적 여러 몰의 정보를 보여주고 있다는 것을 보여드리 위함입니다.
2. 코드 개발을 어떻게 할까
먼저 크롬드라이브와 셀레니움, openpyxl 을 이용하여 다나와 사이트 정보를 받아 오고, 엑셀로 정리할 예정입니다. 엑셀로도 손품을 팔아서 예상 업체 마진, 예상 수입 가격을 분석할 예정입니다. 업계마다 상황이 다르고 마진율도 다를테니 저는 Raw data 정도만 파이썬 코드로 만들 예정입니다.
from selenium.webdriver.common.by import By
from PIL import Image
from openpyxl import Workbook
from openpyxl.drawing.image import Image as ExcelImage
from openpyxl.utils import get_column_letter
from openpyxl.styles import Font, Alignment
import urllib.request
import os
from bs4 import BeautifulSoup
import re
from datetime import datetime
우선 import 하는 모듈은 위와 같습니다.
3. 어떻게 만들까?
페이지를 순회하다보면 같은 제품임에도 불구하고 페이지 수만 늘어나 있는 것을 확인해서 저는 아래와 같이 사용자에게 입력 받도록 했습니다.
1. 검색어를 입력하세요 :
2. 시작 페이지를 입력하세요 :
3. 종료 페이지를 입력하세요 :
먼저 검색어를 입력 받고, 크롤링하는 시작페이지와 검색페이지를 입력 받습니다.
가령, 아이폰15라면 아이폰 15를 입력하고 1페이지,5페이지를 입력하면 아이폰 15 검색어로 1페이지에서 5페이지 까지 크롤링 한 데이터를 엑셀로 저장합니다.
4. 전체 코드는 ?
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
from selenium.webdriver.common.by import By
from PIL import Image
from openpyxl import Workbook
from openpyxl.drawing.image import Image as ExcelImage
from openpyxl.utils import get_column_letter
from openpyxl.styles import Font, Alignment
import urllib.request
import os
from bs4 import BeautifulSoup
import re
from datetime import datetime
def go_to_page(driver, search_query, page_num):
# 검색어를 이용해 URL을 생성합니다.
url = f"https://search.danawa.com/dsearch.php?query={search_query}&originalQuery={search_query}&previousKeyword={search_query}&checkedInfo=N&volumeType=allvs&page={page_num}&limit=40&sort=saveDESC&list=list&boost=true&tab=goods&addDelivery=N&coupangMemberSort=N&isInitTireSmartFinder=N&recommendedSort=N&defaultUICategoryCode=15242844&defaultPhysicsCategoryCode=1826%7C58563%7C58565%7C0&defaultVmTab=331&defaultVaTab=45807&isZeroPrice=Y&quickProductYN=N&priceUnitSort=N&priceUnitSortOrder=A"
driver.get(url)
time.sleep(10) # 페이지 로드 후 10초 동안 대기
def resize_image(image_path, width, height):
# 이미지를 리사이징합니다.
img = Image.open(image_path)
img = img.resize((width, height))
img.save(image_path)
def create_default_image(image_path):
# 기본 이미지를 생성합니다.
default_image = Image.new('RGB', (100, 100), color='white')
default_image.save(image_path)
def clean_filename(filename):
return re.sub(r'[\/:*?"<>|]', '_', filename) # 파일 시스템에서 사용할 수 없는 문자를 밑줄로 대체
def main(search_query, start_page, end_page):
# 크롬 드라이버 경로를 설정합니다.
driver_path = ChromeDriverManager().install()
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
wb = Workbook()
ws = wb.active
ws.append(['상품', '가격', '이미지', '부가정보', '링크', '등록월', '평점', '리뷰 수'])
# 이미지를 저장할 디렉토리를 생성합니다.
image_directory = 'product_images'
if not os.path.exists(image_directory):
os.makedirs(image_directory)
# 기본 이미지 파일 경로
default_image_path = os.path.join(image_directory, "default_image.png")
# 기본 이미지를 생성합니다.
create_default_image(default_image_path)
for page_num in range(start_page, end_page + 1):
go_to_page(driver, search_query, page_num)
product_containers = driver.find_elements(By.CSS_SELECTOR, 'div.prod_main_info')
for container in product_containers:
try:
product_title = container.find_element(By.CSS_SELECTOR, 'div.prod_info > p > a').text
product_price = container.find_element(By.CSS_SELECTOR,
'div.prod_pricelist > ul > li > p.price_sect > a > strong').text
# 등록월 정보 추출
registration_month = container.find_element(By.CSS_SELECTOR,
'div.prod_sub_info > div.prod_sub_meta > dl.meta_item.mt_date > dd').text
# 평점 정보 추출
rating = container.find_element(By.CSS_SELECTOR,
'div.prod_sub_info > div.prod_sub_meta > dl.meta_item.mt_comment > dd > div.cnt_star > div.point_num > strong').text
# 리뷰 수 정보 추출
review_count = container.find_element(By.CSS_SELECTOR,
'div.prod_sub_info > div.prod_sub_meta > dl.meta_item.mt_comment > dd > div.cnt_opinion > a > strong').text
except:
product_price = "가격 정보 없음"
registration_month = "등록월 정보 없음"
rating = "평점 정보 없음"
review_count = "리뷰 수 정보 없음"
product_image_tag = container.find_element(By.CSS_SELECTOR, 'div.thumb_image > a > img')
# Lazy Loading된 이미지의 URL을 가져옵니다.
lazyloaded_url = product_image_tag.get_attribute('data-src')
# URL이 존재하는지 확인합니다.
if lazyloaded_url is not None:
# URL을 완전한 형태로 수정합니다.
if lazyloaded_url.startswith('//'):
lazyloaded_url = 'https:' + lazyloaded_url
# 이미지를 다운로드합니다.
image_filename = clean_filename(product_title) + ".png"
image_path = os.path.join(image_directory, image_filename)
urllib.request.urlretrieve(lazyloaded_url, image_path)
# 이미지를 리사이징합니다.
resize_image(image_path, width=100, height=100)
# 이미지를 엑셀에 추가합니다.
img = ExcelImage(image_path)
else:
# Lazy Loading된 이미지가 없는 경우에는 기본 이미지를 사용합니다.
img = ExcelImage(default_image_path)
# 부가정보를 가져옵니다.
try:
additional_info = container.find_element(By.CSS_SELECTOR, 'div.spec_list').text
except:
additional_info = "부가정보 없음"
# 제품 링크를 가져옵니다.
product_link = container.find_element(By.CSS_SELECTOR, 'a.thumb_link').get_attribute('href')
ws.append([product_title, product_price, '', additional_info, product_link, registration_month, rating,
review_count])
# 셀에 이미지를 추가합니다. 여기서 좌표는 맞춰서 수정해야 합니다.
ws.add_image(img, f'C{ws.max_row}') # 현재 엑셀 행에 이미지 추가
# 링크 셀에 하이퍼링크를 추가합니다.
link_cell = ws[f'E{ws.max_row}']
link_cell.value = "제품 링크"
link_cell.font = Font(color='0563C1', underline='single')
link_cell.alignment = Alignment(horizontal='center')
ws[f'E{ws.max_row}'].hyperlink = product_link
ws[f'E{ws.max_row}'].style = 'Hyperlink'
# 현재 날짜를 가져옵니다.
today_date = datetime.today().strftime('%Y-%m-%d')
# 파일명을 생성합니다.
filename = f"온라인_시장조사_{search_query}_{today_date}.xlsx"
# 엑셀 파일을 저장합니다.
wb.save(filename)
if __name__ == '__main__':
search_query = input("검색어를 입력하세요: ")
start_page = int(input("시작 페이지를 입력하세요: "))
end_page = int(input("종료 페이지를 입력하세요: "))
main(search_query, start_page, end_page)
자! 이렇게 하면, 페이지를 다운 받아서 엑셀로 저장하게 됩니다!
공부용으로 사용하시고, 상업용이나 서버에 부하를 주는 행위는 위법 행위가 될 수 있으니
각자 알아서 사용하세요!
감사합니다.

{kind=link}